Replacing the Nodes in an AWS ElasticSearch Cluster
In a previous post, I talked about how I have tended towards the philosophy of ‘Immutable Infrastructure’. As part of that philospohy, when a box is created in my environment, it has a lifespan of 14 days. On the 14th day, I get a notification to tell me that the box is due for renewal. When it comes to ElasticSearch nodes, there is a process I follow to renew a box.
I have an example 3 nodes cluster of ElasticSearch up and running to test this on:
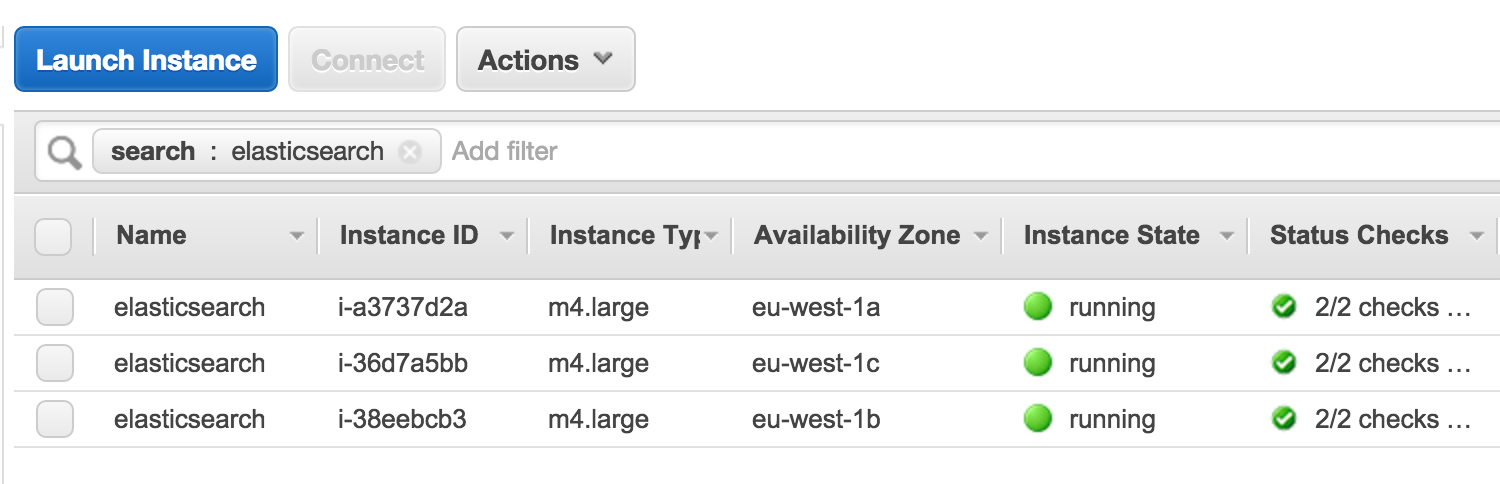
Let’s assume that instance i- was due for renewal. Firstly, I would usually disable shard reallocation. This will stop unnecessary data transfer between nodes and minimise the wastage of I/O.
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.enable" : "none"
}
}'
As these shard allocation is now disabled, I can continue with the node replacement. There are a few ways to do this. Previously to ElasticSearch 2.0, we could do it with the ElasticSearch API:
curl -XPOST 'http://localhost:9200/_cluster/nodes/MYNODEIP/_shutdown'
If you are using ElasticSearch 2.0, you are more than likely running ElasticSearch as a service. To shutdown the node, stop the service.
By looking at the status of the cluster now, I can see the following:
curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 160,
"active_shards" : 317,
"relocating_shards" : 0,
"initializing_shards" : 2,
"unassigned_shards" : 151,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0
}
I can see that it tells me the cluster is yellow and that I have 2 nodes in it. I can proceed with the instance termination.
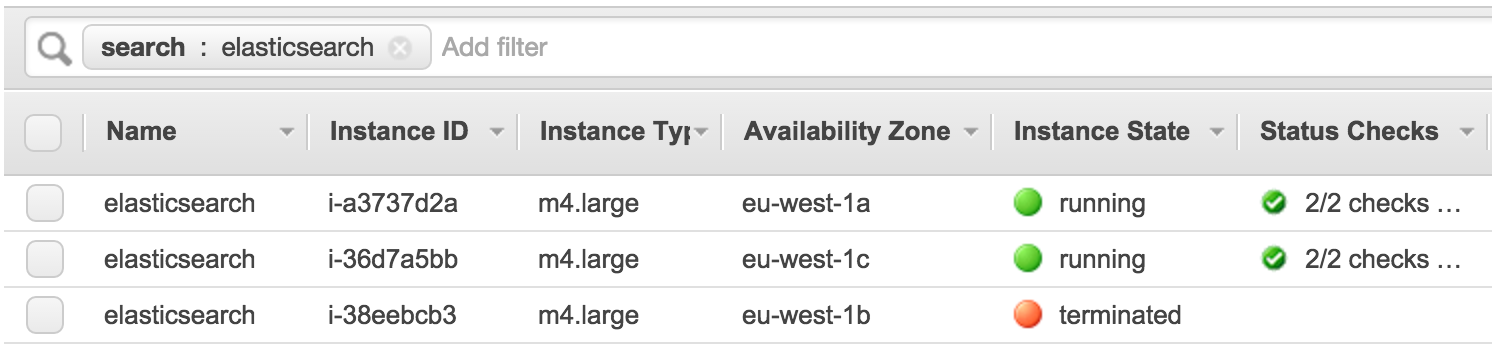
I have an AWS Autoscale Group configured for ElasticSearch to keep 3 instances running. Therefore, the node that I destroyed will fail the Autoscale Group Healthcheck and a new instance will be spawned to replace it.
Using the ElasticSearch Cluster Health API, I can determine when the new node is in place:
curl -XGET 'http://localhost:9200/_cluster/health?wait_for_nodes=3&timeout=100s'
The command will continue running until the cluster has 3 nodes in it. If you want to replace more nodes in the cluster, then repeat the steps above. If you are finished, then it is important to re-enable the shard reallocation:
curl -XPUT localhost:9200/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.enable" : "all"
}
}'
The time taken to rebalance the cluster will depend on the number and size of the shards.
You can monitor the health of the cluster until it turns green:
curl -XGET 'http://localhost:9200/_cluster/health?wait_for_status=green&timeout=100s'
The cluster is now green and all is working as expected again:
curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 160,
"active_shards" : 470,
"relocating_shards" : 1,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0
}